大量のデータをLevelDBに初期投入するとき、put したエントリ数が増えるにつれて、1件あたりの投入時間が増えていくという状況があり、その理由を探るために、手っとり早く使えそうな Java のプロファイリングツールとして、VisualVM をインストールして使用してみました。
ダウンロード
https://visualvm.github.io/download.html
インストールと起動
ダウンロードした .zip を解凍します。実行ファイルは bin 配下にあります。
使用している OS に適したバイナリを実行して VisualVM を起動します
visualvm\bin\visualvm.exeまたは、
visualvm/bin/visualvm
コマンドライン引数として、JDK Home や VisualVM ユーザーディレクトリを定義するオプションを設定することもできます。
--jdkhome "<path to JDK>" --userdir "<path to userdir>"使ってみる
次のような、あえてメモリリークを発生させるプログラムを実行してみます。
public class MemoryLeak {
public static class Data {
Long[] _data;
public Data(Long[] data) {
_data = data;
}
}
Map<String, Data> _map;
public MemoryLeak() {
_map = new HashMap<>();
}
// これを呼び出すと、 _map に data が蓄積されていく
public void doSomeProcess(String key, Long[] data) {
_map.put(key, new Data(data));
}
}テストプログラム。
public class MemoryLeakTest {
@Test
void testMemoryLeak() {
var leak = new MemoryLeak();
for (int i = 0; i < 1000; ++i) {
String key = "key_" + i;
Long[] data = new Long[1000000]; // 約8MBの配列を作って
leak.doSomeProcess(key, data); // それをリークさせる
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
if (((i+1) % 10) == 0) {
System.out.println("count = " + (i+1));
}
}
}
}Eclipse の JUnit から上記テストプログラムを起動します。左側のペインに起動された Java プロセスが表示されるので、それをダブルクリックします。
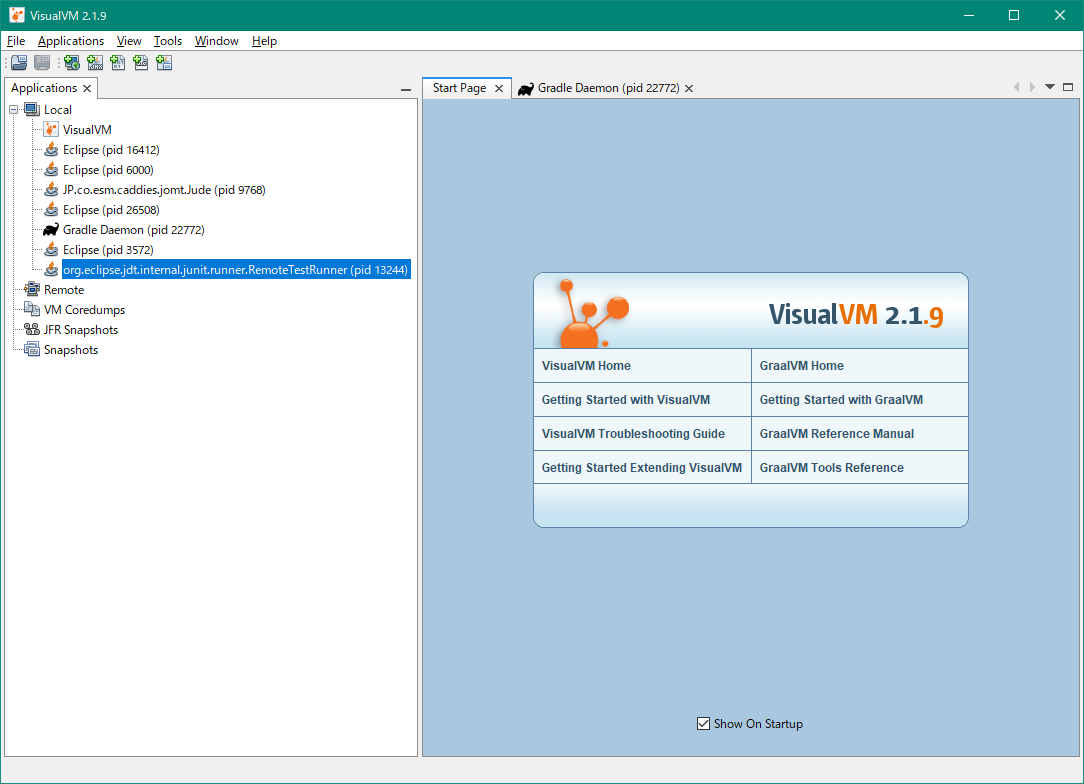
右側のペインで、「Monitor」タブをクリックします。下図のような4つのチャートが表示されます。右上のチャートがメモリの使用状況です。これを見ると、メモリの使用量が着実に増えていくのが見てとれるかと思います。
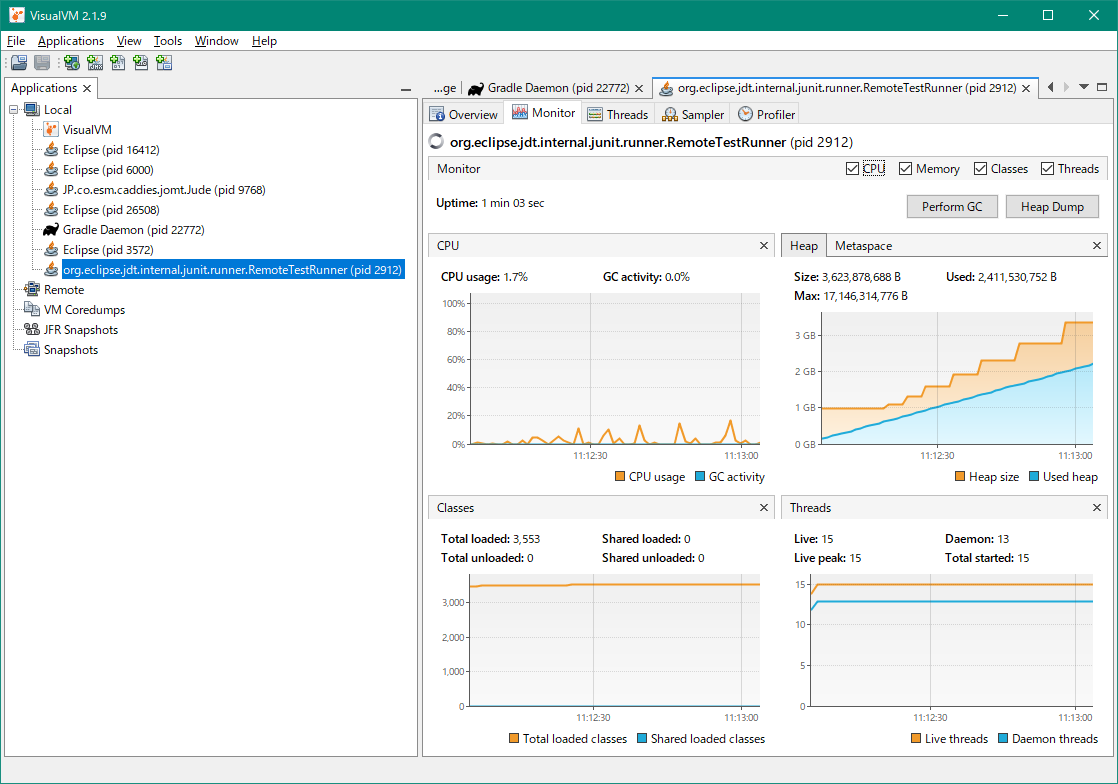
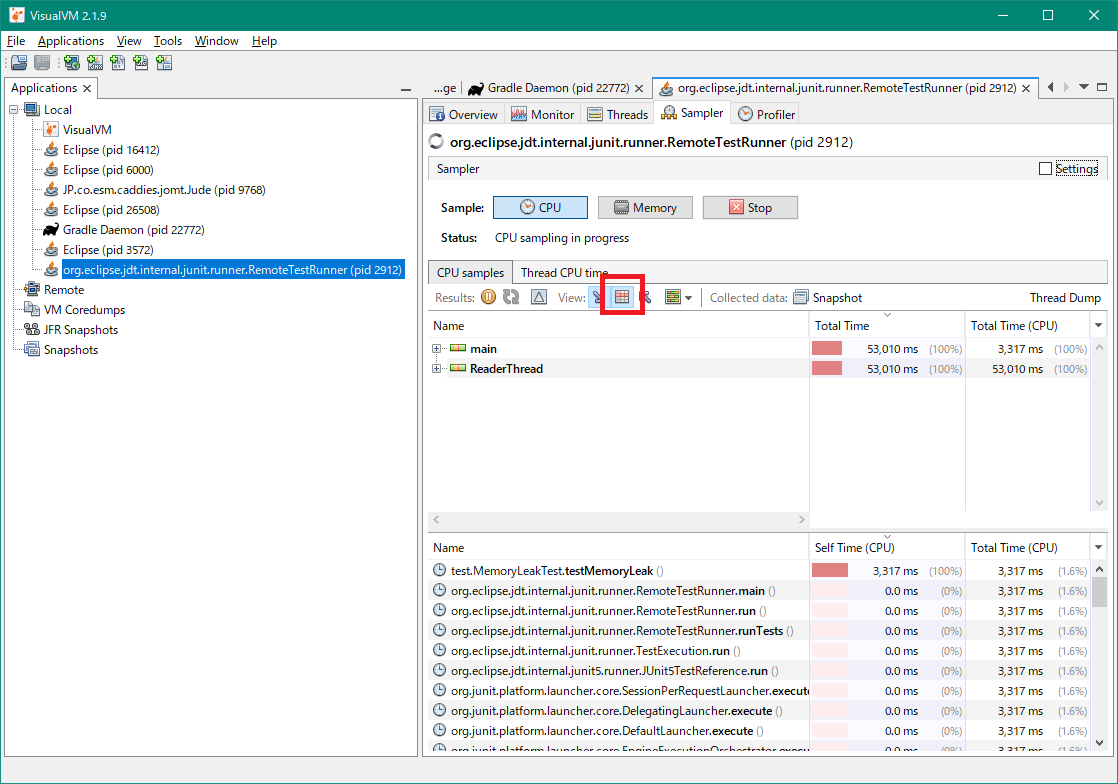
次はCPUの使用状況です。「Sampler」タブをクリックし、「CPU」ボタンをクリックします。さらに赤枠で囲んだボタンもクリックしておきましょう。下図のように、呼び出し階層ごとのCPU使用率と、CPUを食っている順にメソッドを並べた「ホットスポット」が表示されます。
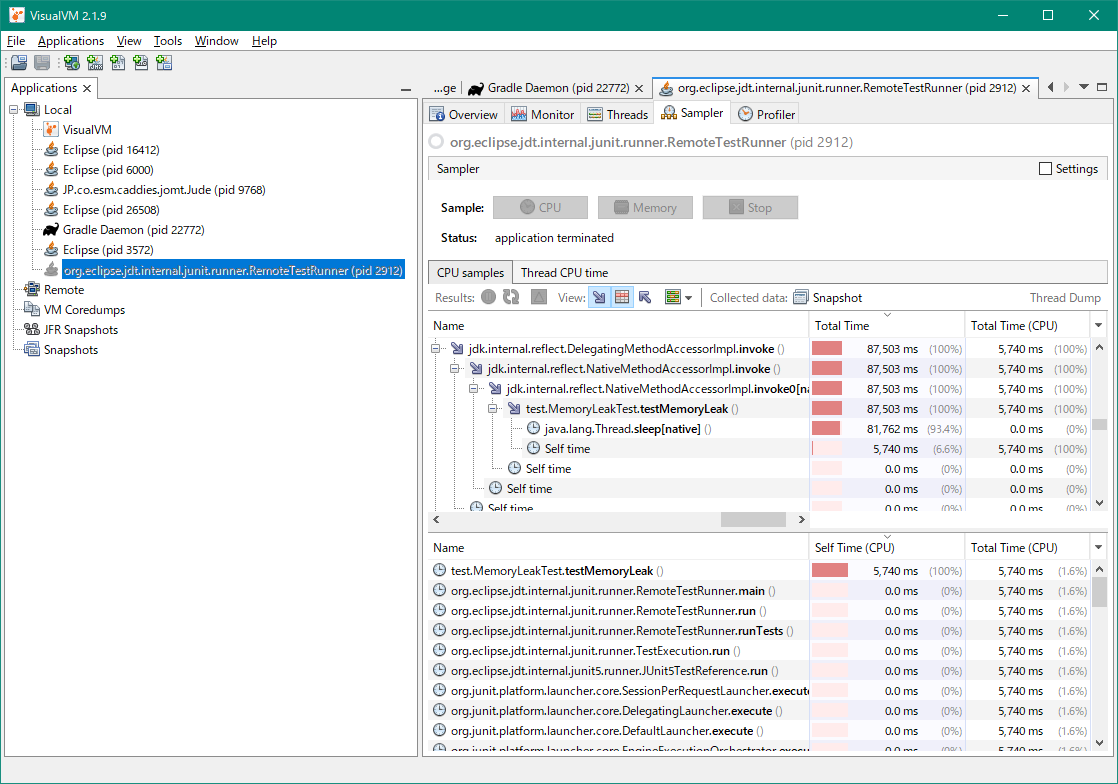
階層ごとの画面では、「+」をクリックして階層を開くと下位層が表示されます。下図は一番下の層まで開いたところを示しています。
おまけ
LevelDBへの大量データ初期投入の話に戻りましょう。
VisualVMを使っていろいろと探っていったところ、どうやら、いわゆる「Negative Hit」(存在しないエントリを読みにいくこと)が多発しており、それが時間がかかった原因の一つだということが分かりました。

これを抑制するために、BitSet を用いて、「このキーは確実に未登録である」ということが分かる場合は、LevelDB の get() を呼ばずに直ちに null を返す、という方策を取りました。
具体的には、LevelDB のキーである byte[] のハッシュ値を計算し、set() のときはそのハッシュ値の位置の bit を ON にセットし、get() のときはそのハッシュ値の位置の bit を調べます。ハッシュ値の衝突が発生した場合は、bit が ON であっても Negative Hit の可能性がありますが、bit が OFF ならそのキーは確実に未登録である、と判定できます。
他にもキャッシュ戦略の見直しなども行い、結果的に初期投入時間を半分以下に減らすことができました。