
はじめに
先日開催の社内勉強会では、書籍『Pythonではじめる 情報検索プログラミング』を教材として、情報検索について学びました。
本記事では、その勉強会で扱った内容のうち、「文書のクラス分類」について整理します。文書のクラス分類とは、あらかじめ定められた分類に従って、未知の文書がどのクラスに属するかを推定する手法です。
今回は、クラスタリングとの違いを確認した上で、機械学習による分類の枠組み、代表的な分類モデル、モデルの評価方法、チューニング手法について学んでいきます。
書籍リンク:https://www.morikita.co.jp/books/mid/081861
データのクラス分類:あらまし
文書やデータをグループに分ける考え方として、次の二つがあります。
- クラスタリング(前章まで)
- クラス分類(今回)
両者は、データをグループに分けるという点では共通しています。しかし、分け方に対する考え方が異なります。
クラスタリングでは、データ同士の特徴の近さをもとに、どのようなグループが存在するかを発見します。あらかじめ正解となる分類は与えられていません。
一方、クラス分類では、あらかじめ「この文書はこの分類に属する」という正解が与えられています。その正解付きのデータをもとに、未知の文書に対しても正しい分類を予測できるようにすることを目指します。
つまり、クラスタリングが分類の「発見」を目的とするのに対し、クラス分類は分類の「学習」を目的とする手法であると整理できます。
7.1 機械学習の枠組み
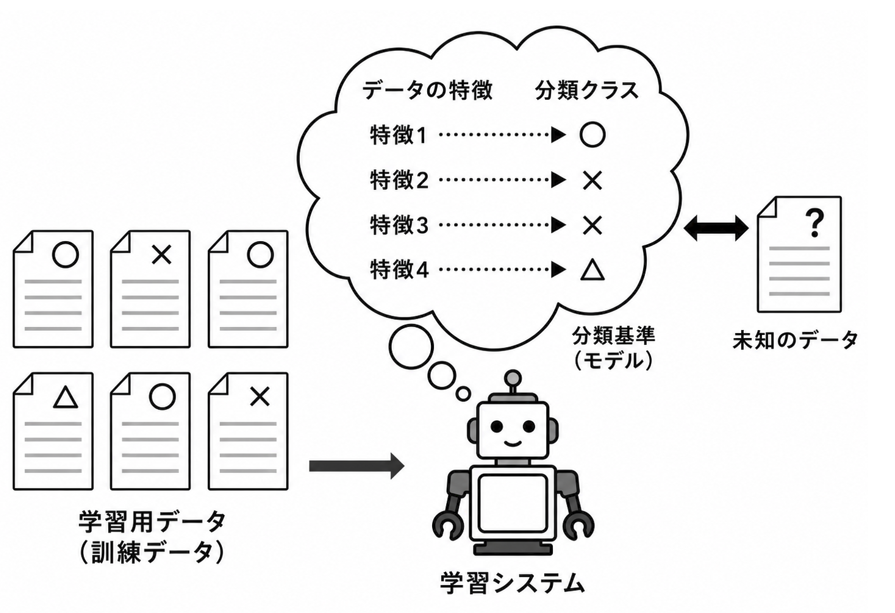
機械学習によるクラス分類では、まず、正解が付与された文書を学習データとして用意します。
例えば、ニュース記事を「スポーツ」「経済」「技術」といった分類に分けたい場合、あらかじめ人間が分類した記事を分類機に与えます。分類機は、各文書に現れる単語などの特徴と、正解となる分類との関係を学習します。
学習後は、分類が分かっていない新しい文書を入力します。分類機は、学習した関係をもとに、その文書がどの分類に属するかを予測します。
このように、正解付きのデータを使って未知のデータを分類する学習方法を、教師あり学習と呼びます。
7.2 分類機(モデル)の種類
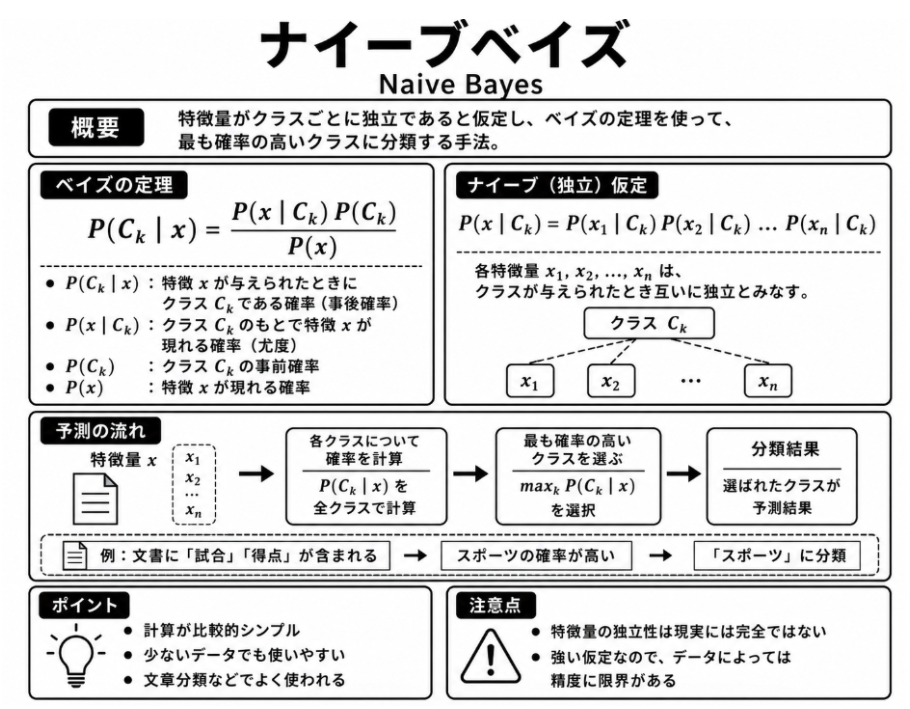
7.2.1 ナイーブベイズ
ナイーブベイズは、ある文書が各分類に属する可能性を、文書内に現れる単語の傾向から判断する分類モデルです。
例えば、技術に関する文書には「通信」「ネットワーク」「API」といった単語が現れやすく、スポーツに関する文書には「試合」「選手」「得点」といった単語が現れやすいと考えられます。
学習データからこのような傾向を把握しておけば、未知の文書に「通信」や「ネットワーク」といった単語が多く含まれているとき、その文書は技術に関する分類に属する可能性が高いと判断できます。
ナイーブベイズの「ベイズ」は、ある文書が与えられたときに、その文書がどの分類に属しやすいかを確率的に判断する考え方に由来します。
一方、「ナイーブ」と呼ばれる理由は、文書内の単語同士の関係を単純化して扱う点にあります。実際には、「機械」と「学習」や、「通信」と「ネットワーク」のように、同時に現れやすい単語があります。しかし、ナイーブベイズでは、分類が決まっている前提では、各単語は互いに独立して現れるものとして扱います。
現実を完全に表している仮定ではありませんが、計算が簡単であり、文書分類では有効に働く場合があることが特徴です。
7.2.2 サポートベクトルマシン
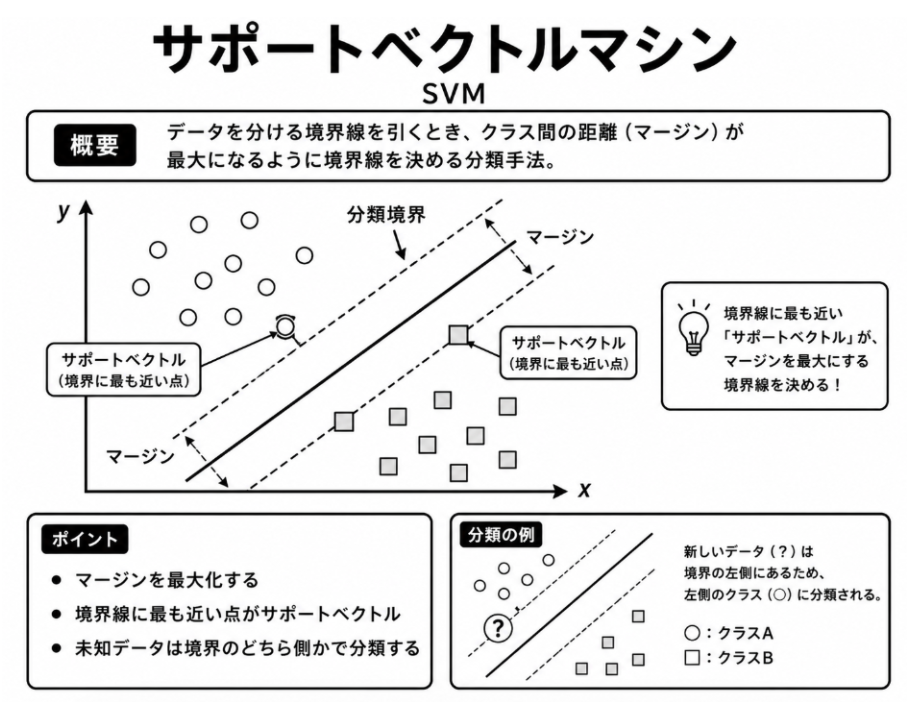
サポートベクトルマシン(SVM)は、異なる分類のデータを分ける境界を求める分類手法です。
二つの分類を分ける境界は、複数考えられる場合があります。その中でSVMは、境界に最も近いデータとの距離ができるだけ大きくなる境界を選びます。この境界とデータとの距離を、マージンと呼びます。
境界付近のデータにぎりぎり合わせた分類では、新しいデータが少し変化しただけで誤って分類される可能性があります。一方、マージンを広く取った境界を選ぶことで、未知のデータに対しても安定して分類しやすくなります。
7.3 分類機(モデル)の評価
7.3.1 汎化性能が重要である
学習において大切なのは、教わった問題をそのまま解けることだけではありません。学習した考え方をもとに、まだ見たことのない問題にも対応できることが重要です。
分類機でも同様に、学習に使った文書を正しく分類できるだけでは十分ではありません。未知の文書に対しても正しく分類できることが重要です。
このように、学習していない新しいデータに対しても適切に予測できる性能を、汎化性能と呼びます。
分類機を評価する際には、学習データに対する成績だけでなく、未知のデータに対する汎化性能を確認する必要があります。
そのための方法の一つが、交差検証です。交差検証では、用意したデータを学習用と評価用に分け、次の流れで性能を確認します。
- 学習用のデータを使って分類機を学習させる
- 学習結果をもとに分類モデルを構築する
- 評価用のデータを使って、未知のデータに対する分類性能を確認する
7.3.2 K分割交差検証
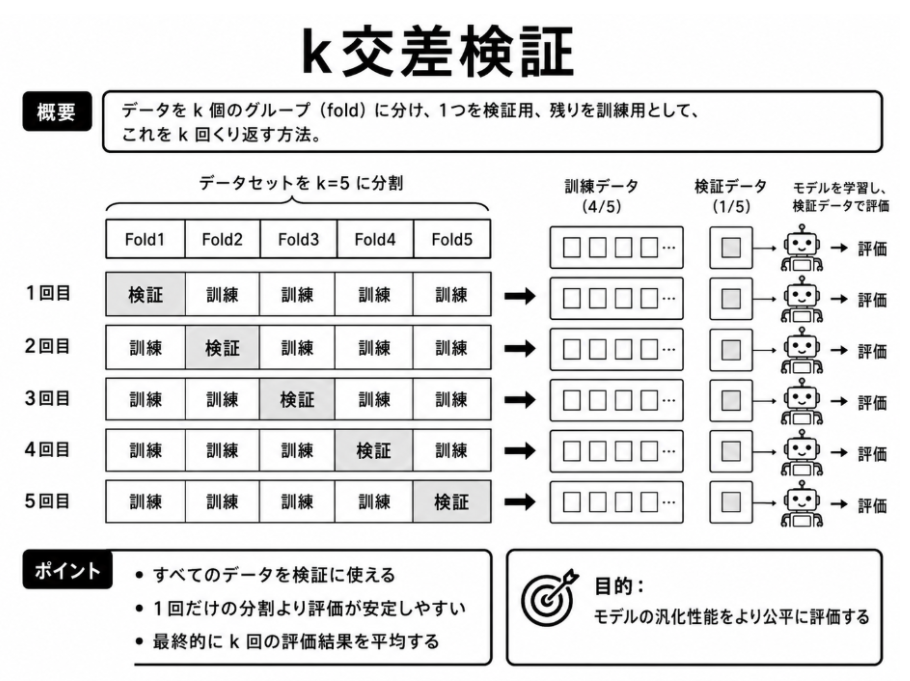
K分割交差検証では、手元のデータをK個のグループに分割します。そのうち一つを評価用のデータ、残りを学習用のデータとして分類機の性能を確認します。
次に、評価用として使うグループを入れ替えながら、同じ評価をK回繰り返します。最後に、各回の評価結果を平均し、分類機の性能として扱います。
一度だけ学習用と評価用を分ける場合、たまたま評価しやすいデータや評価しにくいデータが選ばれてしまい、結果が偏る可能性があります。K分割交差検証を使うことで、データの分け方による偏りを抑え、分類機の性能をより安定して評価できます。
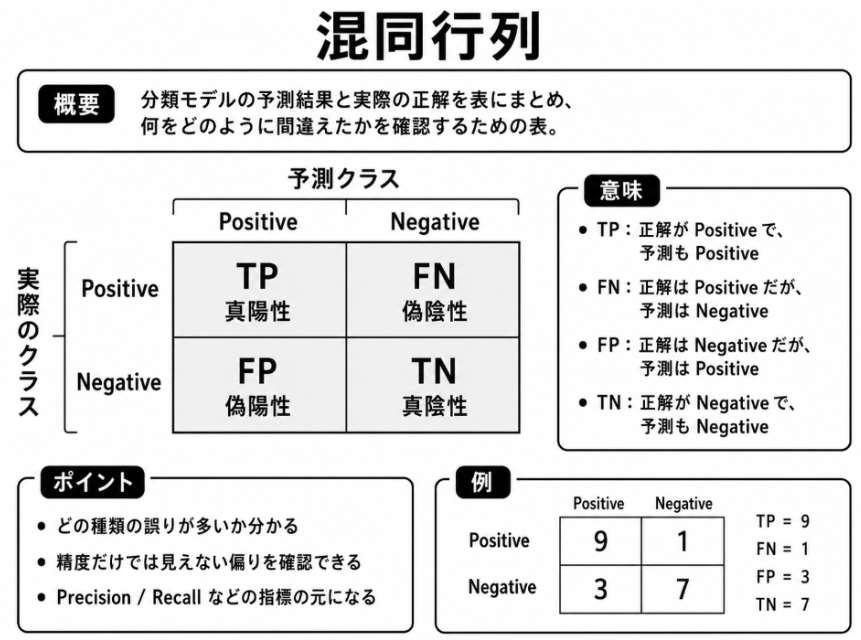
7.3.3 混同行列
分類機の評価では、正解率だけを見ると、どのような間違いが起きているのかが分かりません。
例えば、三つの分類を扱う場合、単に「正解率が低い」と分かるだけでなく、次のような状況を確認したい場合があります。
- 技術に関する文書を、経済に関する文書として誤って分類している
- スポーツに関する文書だけ、特に分類精度が低い
- 特定の二つの分類が、互いに取り違えられやすい
このように、正解となる分類と、分類機が予測した分類との組み合わせを表形式に整理したものが、混同行列です。
混同行列を見ることで、分類機がどの分類を正しく判断できているのか、また、どの分類同士を取り違えやすいのかを確認できます。その結果、学習データが不足しているのか、分類の特徴が似すぎているのか、モデルの調整が必要なのかを考える手がかりになります。
7.4 分類機(モデル)のチューニング
7.4.1 ハイパーパラメータチューニング
分類モデルには、学習を始める前に人間が設定する調整値があります。これをハイパーパラメータと呼びます。
ハイパーパラメータの設定によって、分類モデルの性能は変化します。例えば、SVMでは、誤分類をどの程度許容するかや、データの境界をどのように考えるかに関する設定が性能に影響します。
そのため、分類機の性能を高めるには、学習に使うデータやモデルの種類だけでなく、ハイパーパラメータの設定も調整する必要があります。この調整を、ハイパーパラメータチューニングと呼びます。
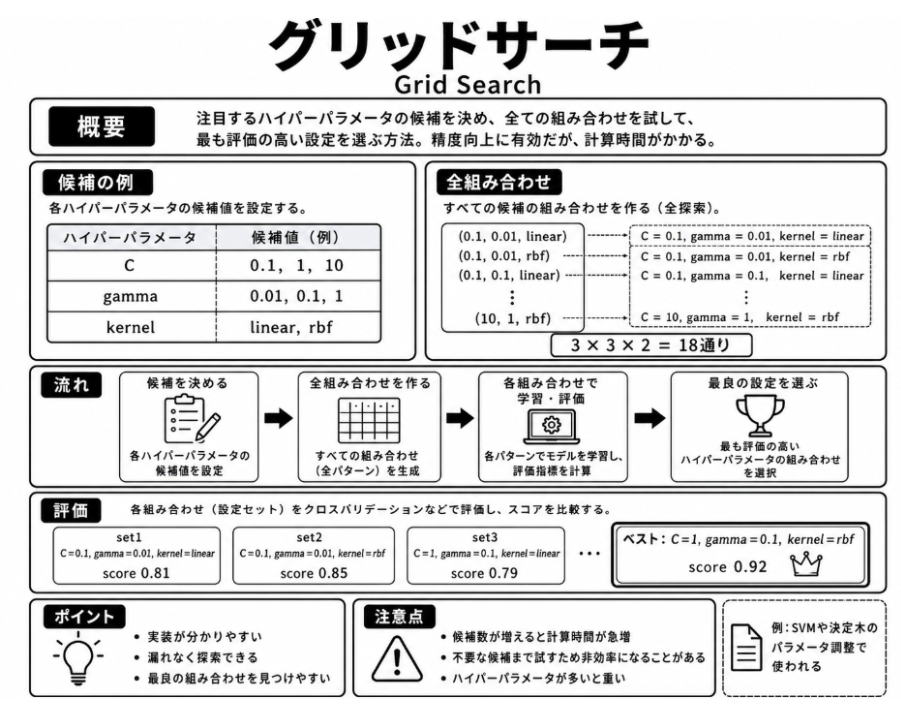
7.4.2 グリッドサーチ
グリッドサーチは、注目するハイパーパラメータについて複数の候補値を用意し、その組み合わせを一通り試す方法です。
例えば、二種類の調整項目について、それぞれ三つずつ候補値を用意した場合、合計九通りの組み合わせを試し、それぞれの性能を比較します。その中で、最も良い評価結果が得られた組み合わせを採用します。
グリッドサーチは、候補となる設定を漏れなく比較できる点が分かりやすい手法です。一方で、調整項目や候補値が増えるほど、試す組み合わせも増え、評価に時間がかかるという特徴があります。
参考:条件付き確率とベイズの考え方
ナイーブベイズを理解する上では、条件付き確率とベイズの考え方を確認しておくと理解しやすくなります。
条件付き確率とは、ある出来事が起きたという前提のもとで、別の出来事が起きる可能性を考えるものです。
例えば、「山田さんが熱中症で倒れてしまった」という状況を考えます。この状況が分かっている場合、「山田さんが119番通報された」可能性は高くなると考えられます。一方、「山田さんがケーキを食べた」可能性については、熱中症で倒れたという情報から直接高くなるとは考えにくいでしょう。
このように、ある前提となる情報が与えられることで、別の出来事が起こる可能性の見方が変わります。
文書分類でも同じように考えます。
分類機が判断したいのは、「この文書が与えられたとき、この文書はどの分類に属する可能性が高いか」です。
そのために、学習データから次のような情報を利用します。
- ある分類では、どのような単語を含む文書が現れやすいか
- それぞれの分類自体が、学習データの中でどの程度現れているか
例えば、技術に関する分類の文書で「通信」「ネットワーク」という単語が現れやすく、未知の文書にもそれらの単語が多く含まれている場合、その文書は技術に関する分類である可能性が高いと判断できます。
ベイズの考え方は、このように「分類ごとの文書の現れやすさ」と「分類自体の現れやすさ」を組み合わせ、与えられた文書がどの分類に属しやすいかを考える枠組みです。