

LLM Knowldge graph builderとは?
- 非構造化データ(ローカルファイル、Webソース、YouTubeの動画等)をチャンク分割 → ベクトル化&ナレッジグラフ化するNeo4j社のツール。
対応されているローカルファイル
| ファイルタイプ | サポートされている拡張子 |
|---|---|
| Microsoft Office | .doxc、 .pptx、 .xls |
| 画像 | .jpeg、 .jpg、 .png、 .svg |
| 文章 | .html、 .txt、 .md |
- Google Cloud StorageやAmazon S3などをデータソースとして接続するすることも可。
- 構築したナレッジグラフをもとに、RAGすることもできる。
- Graph DB本体は、「Aura DBインスタンス」「Neo4j Desktop」「Docker Neo4j」に構築可能。
- Aura DBインスタンスでは現行、利用できるLLMモデルが限られている。ローカルLLMや、その他LLMモデルを利用したい場合は、Desktop版かDocker版の利用を推奨。
(補足)AuraDBとは?
Neo4j社が提供するクラウドベースのフルマネージド型グラフデータベースサービスのこと。
- 作成したナレッジグラフを強化する機能もある。(用意したグラフスキーマの注入や、グラフの手動調整(重複の調整等))
LLM Knowledge graph builderを試す
準備
公式サイトに手順がわかりやすく書かれている。
- 公式サイト( https://neo4j.com/labs/genai-ecosystem/llm-graph-builder/ )
- 以下の手順で利用準備が整う。
- (1)AuraDBインスタンス立ち上げ
- (2)LLM graph builderとAuraDBインスタンスの接続。
- (3)準備完了。
- 以下の手順で利用準備が整う。
- Desktop版、Docker版を利用したい方は別途LLMのAPIトークンが必要。
非構造化データを読み込む
LLM Knowledge graph builderのトップ画面の左側に各種非構造化データをロードするボタンがある。

それぞれ上から順に、
ローカルファイル、GCP、Amazon S3、Webソース
を表している。
デモ1:Wikipediaのデータを読み込んでみる
(1)Wikipediaのをアップロードすると、PDFがスキャンされ、ロードされる。

▲ データ投入ダイアログ
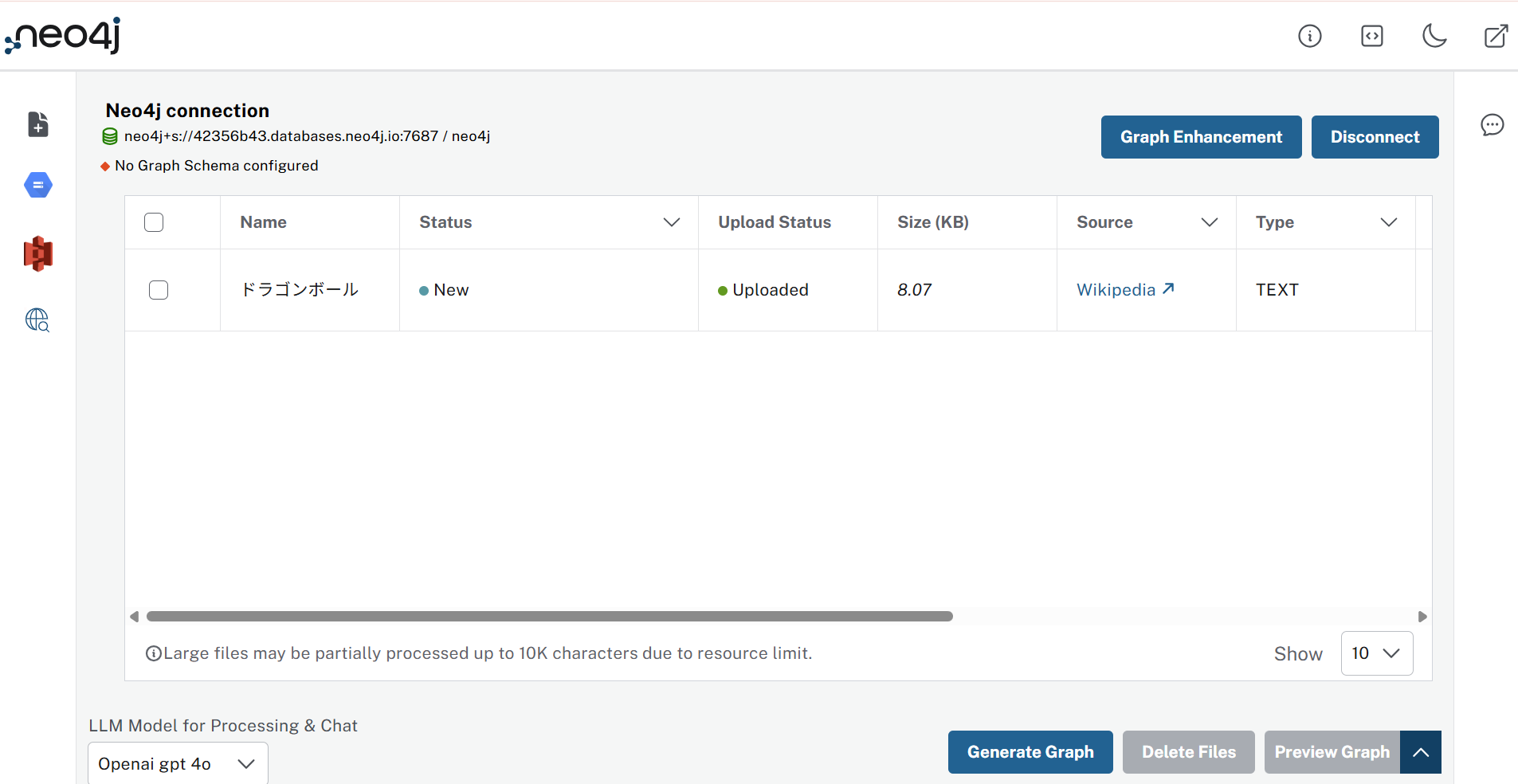
▲ ロード結果
(2)画面右下の「Generate Graph」を押す。このタイミングで、ロードされたWikipediaのテキストがチャンク分割、そしてナレッジグラフが構築される。構築されたグラフは、中央のウィンドウ内から読み込んだデータソースにチェックを入れて、「Preview Graph」を押すことで確認することができる。
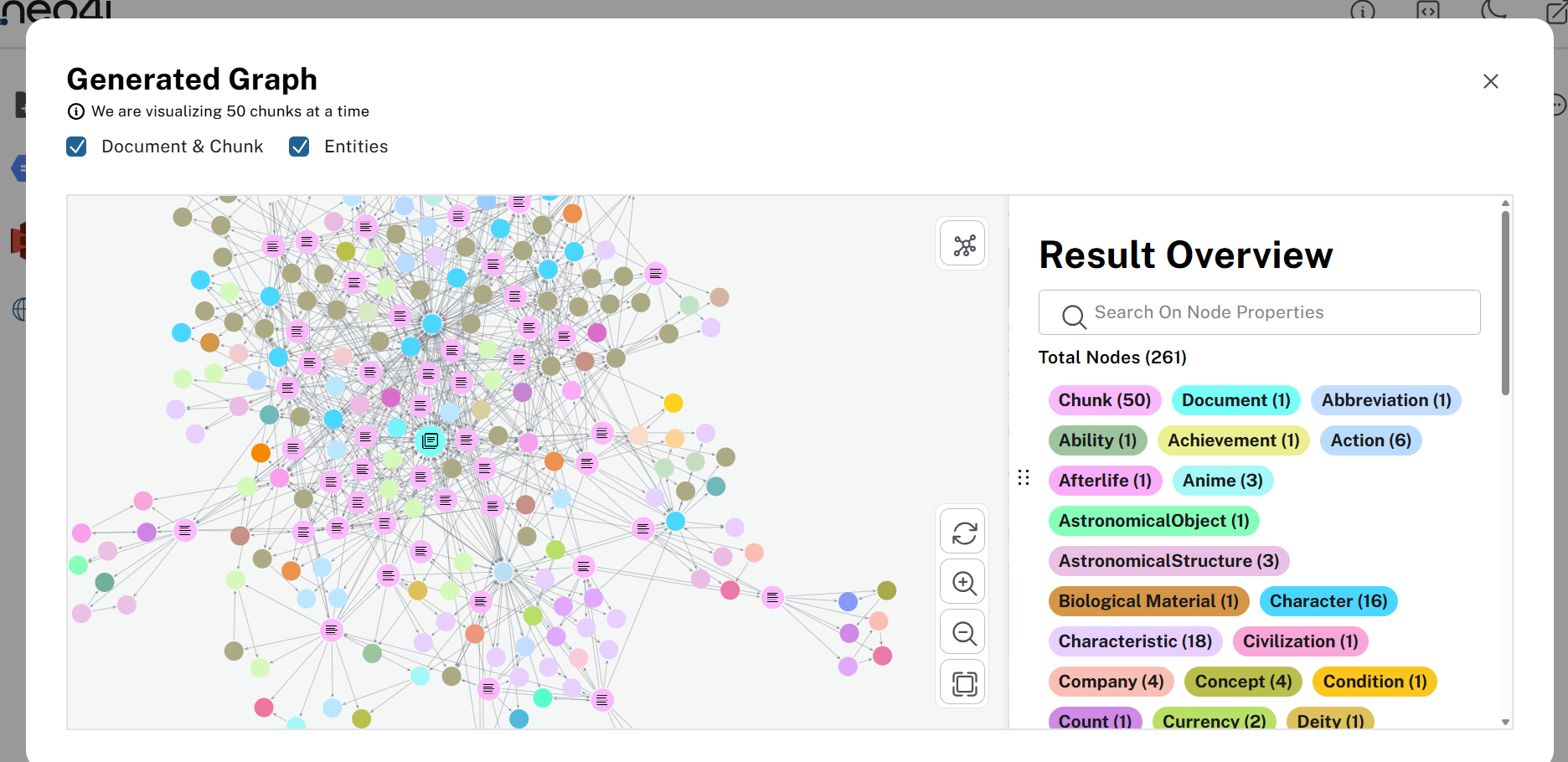
▲ ドラゴンボールのWikipediaページから作成されたナレッジグラフ
(3)画面右側の「Start Chat」ボタンを押すとチャットボットUIが表示される。
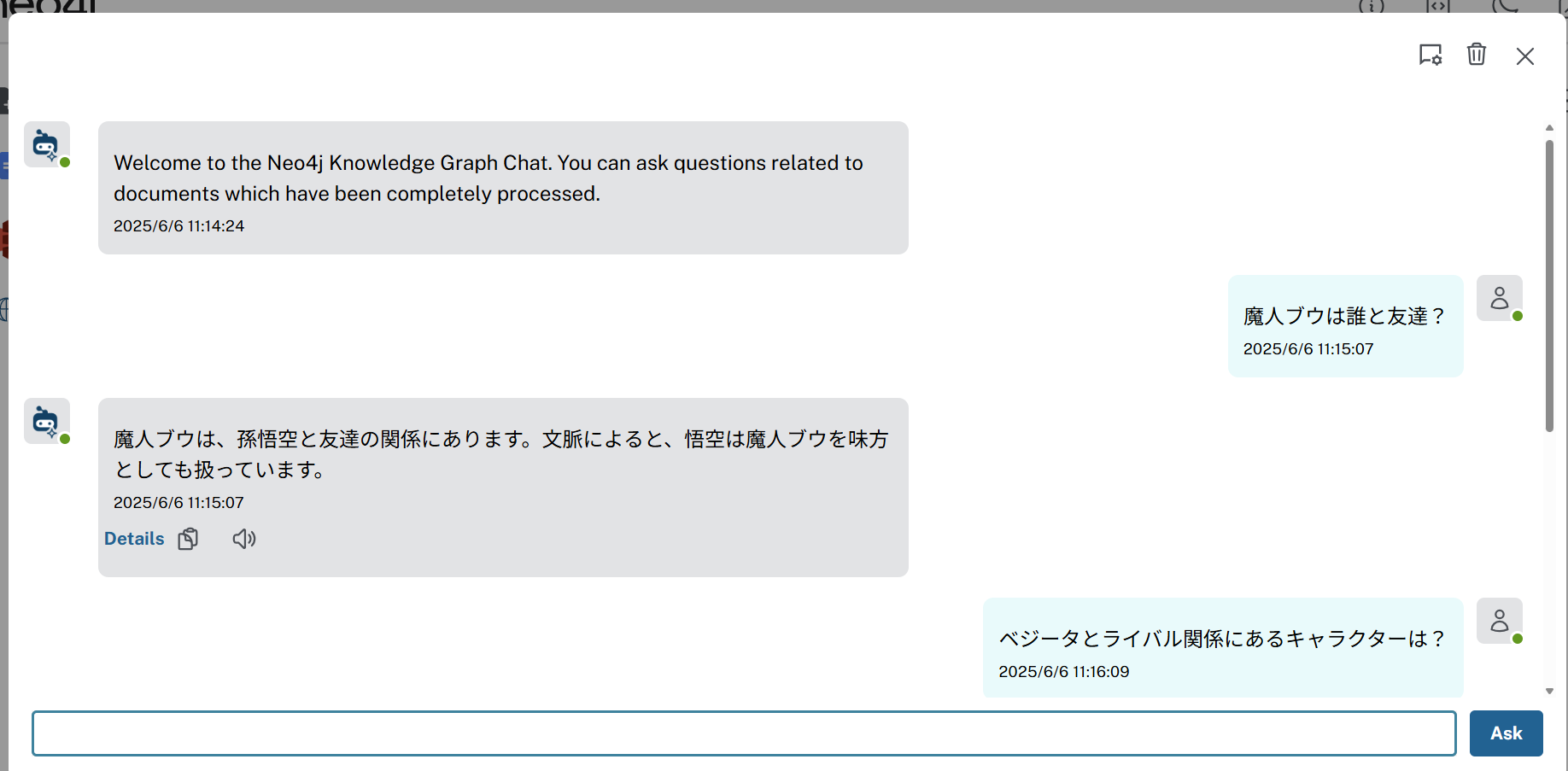
▲ チャットボットUI
デモ2:YouTubeの動画を読み込んでみる
LLM Knowledge graph builder では、YouTubeの動画URLを指定することで、その音声内容を自動で文字起こしし、ナレッジグラフを生成することができる。
(1)左側の「Webソース」アイコンをクリックし、YouTube動画のURLを貼り付ける。
ここでは例として、「WHAT IS JAPAN?」という動画のURLを使用する。

▲ YouTube URLの入力画面
(2)アップロードが完了すると、自動的に動画の音声が文字起こしされ、テキストとして取り込まれる。取り込まれたデータはチャンクに分割され、ベクトル化された後、ナレッジグラフの生成対象として扱われる。
(3)Wikipediaのデモと同様、「Generate Graph」ボタンを押すと、ナレッジグラフが構築される。
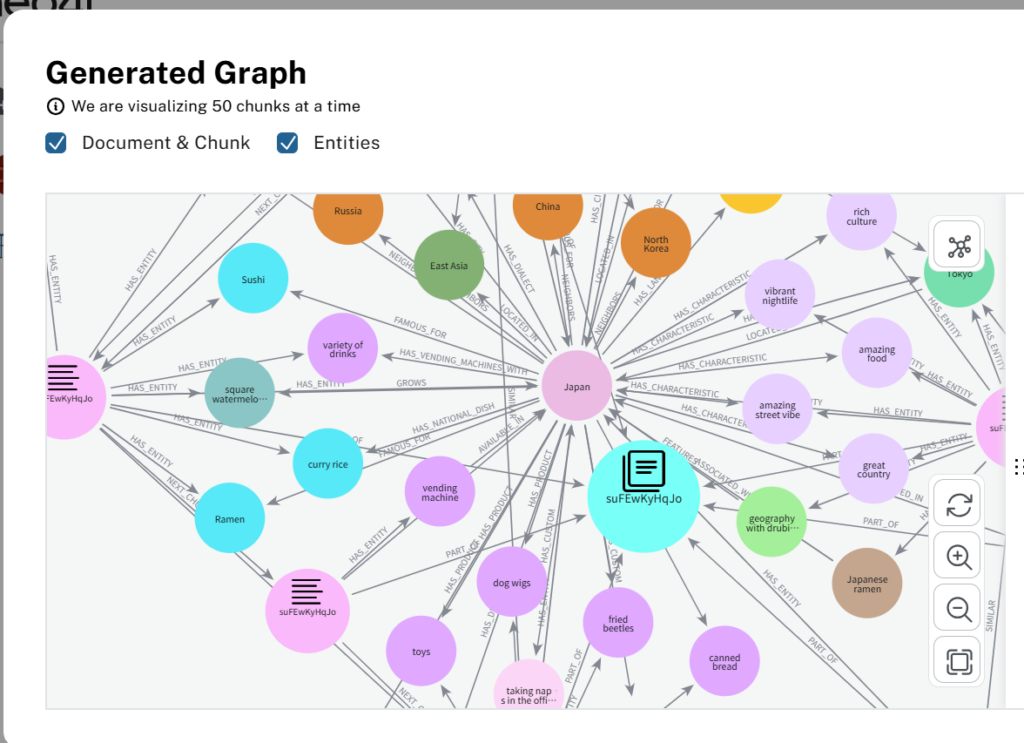
▲ YouTube動画から構築されたナレッジグラフ
(4)構築後は、「Start Chat」で内容について自然言語で質問することが可能になる。
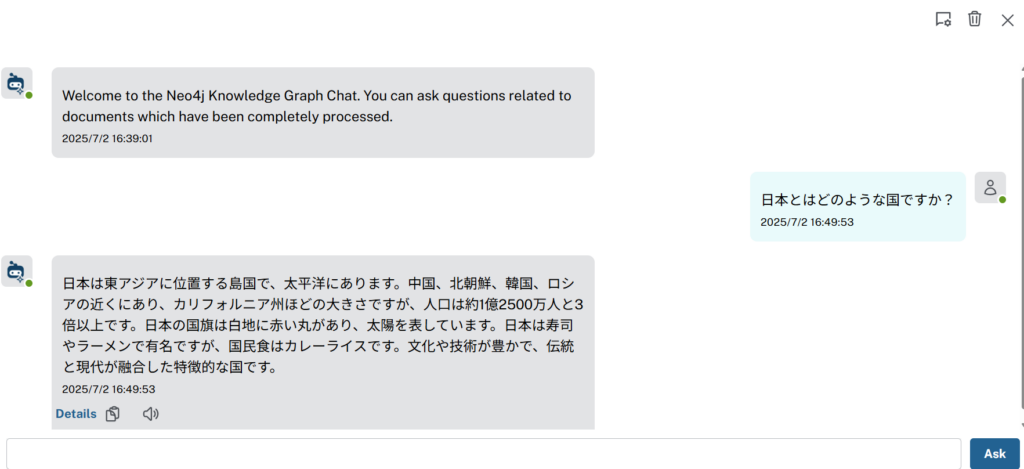
▲ チャットボットUI
おまけ:RAGの処理方法について少しふかぼる
-
LLM Knowledge graph builderのRAG機能、Neo4jがデフォルトで用意しているRAGの処理方法は下記。
- Vector
- Fulltext
- Graph + Vector + Fulltext(GraphRAG Hybrid)
-
Entity Search + Vector
- それぞれの処理方法の説明について、Chat GPT o3曰く

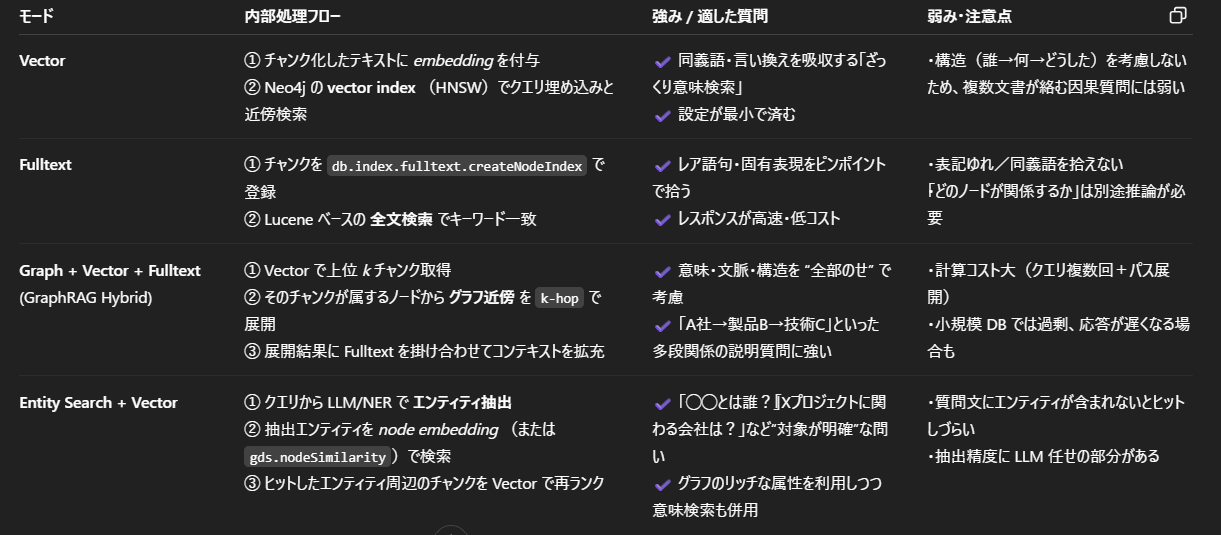
- それぞれの処理方法の説明について、Chat GPT o3曰く