はじめに
GraphRAG(Graph Retrieval-Augmented Generation)は、グラフデータベース(Neo4jなど)の構造的知識と、LLMの自然言語処理能力を統合するアプローチです。
ここでは、dbts2025で紹介したGraphRAGデモプログラムの仕組みを技術的に掘り下げて解説します。
システム全体構成
デモプログラムは以下のコンポーネントで構成されています。
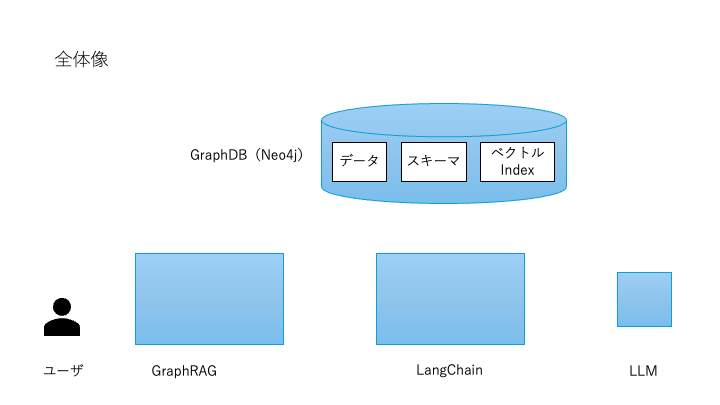
- GraphDB(Neo4j)
業務データを格納する基盤。ノードとリレーションでデータの構造を表現。 - ベクトルIndex
各ノードのテキスト情報(例:部品名・顧客名)を埋め込みモデルでベクトル化し、類似度検索に利用。
デモプログラムではNeo4jのベクトルIndexを利用しました。 - LangChain
RAG処理(検索+生成)を統合的に管理するフレームワーク。 - LLM
自然言語を理解・生成し、Cypherクエリの生成や最終回答の出力を担当。 - ユーザ
自然言語で質問を入力するエンドユーザ。
これにより「自然言語の質問 → グラフDB検索 → Cypher実行 → 回答生成」のフローが自動化されます。
データ投入とベクトル化
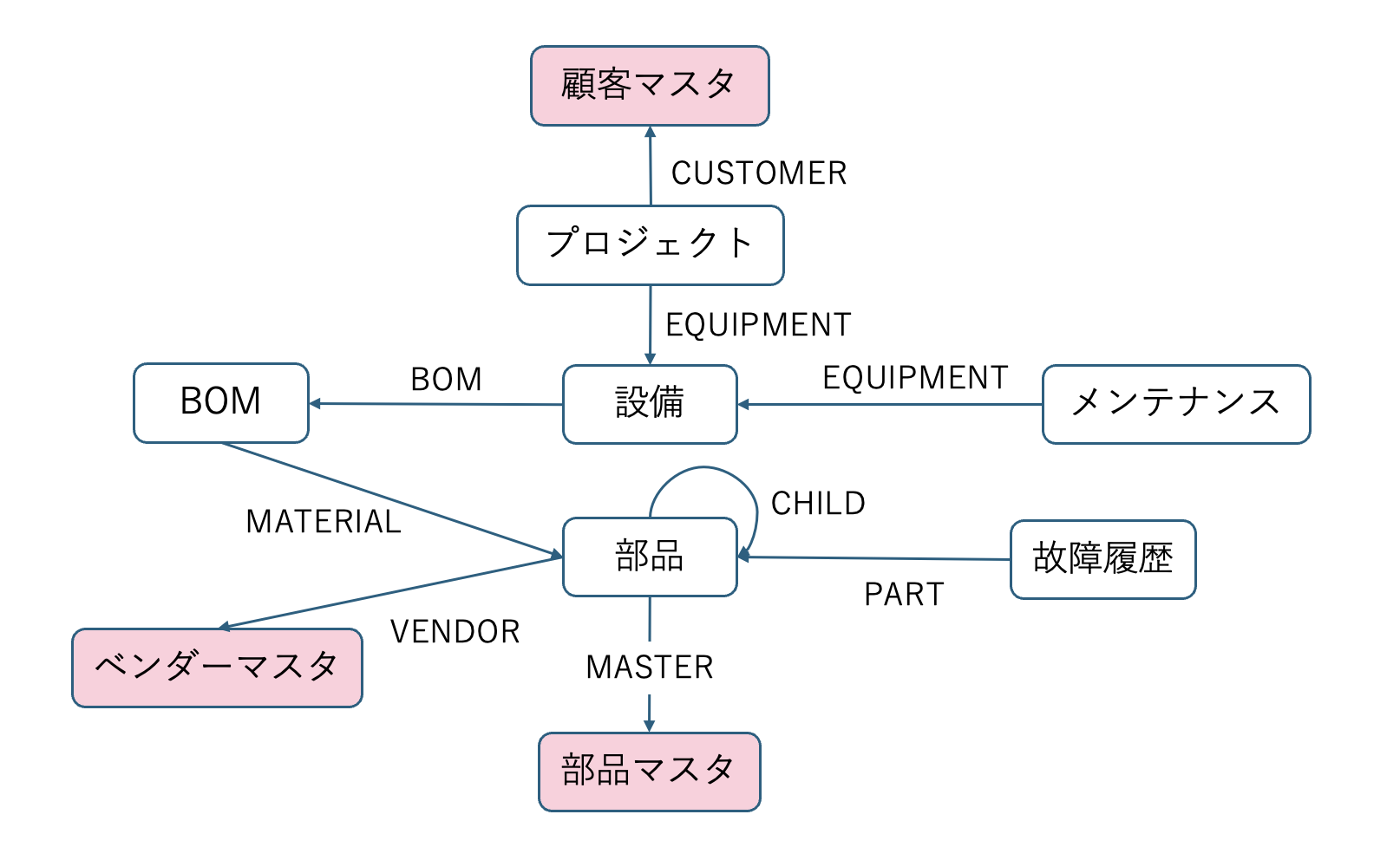
Neo4jには以下のようなノードが投入してあります。
- 顧客マスタ(CustomerMaster)
- プロジェクト(Project)
- 設備(Equipment)
- 部品マスタ(PartMaster)
- 部品(Part)
- ベンダーマスタ(VendorMaster)
- 故障履歴(Failure)
- メンテナンス(Maintenance)
ノードのテキスト情報は ベクトル化され、専用のIndexに保存されます。
この設計により、質問文と意味的に近いノードを高速に検索できる仕組みが実現されます。
質問処理のフロー
-
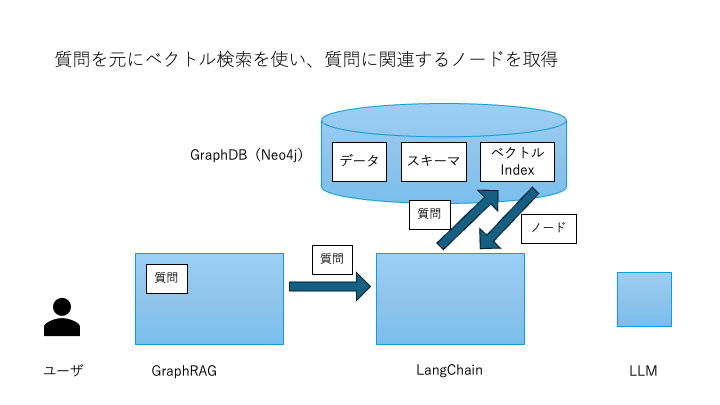
ベクトル検索による関連ノード取得
ユーザが「この設備に含まれる部品は?」といった質問を入力すると、まず質問文を埋め込みベクトルに変換。
→ ベクトルIndexを用いて類似度検索を行い、関連するノード候補を抽出します。
-
スキーマの取得
次に、GraphDBのスキーマ情報を取得します。
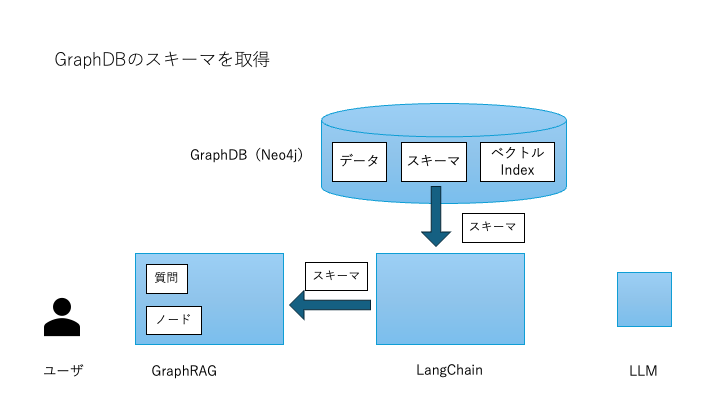
取得したスキーマの例:(:Project)-[:CUSTOMER]->(:CustomerMaster) (:Equipment)-[:BOM]->(:BOM) (:BOM)-[:MATERIAL]->(:Part) (:Part)-[:MASTER]->(:PartMaster)これにより、質問に関連するノード間の接続パターンを特定できます。
-
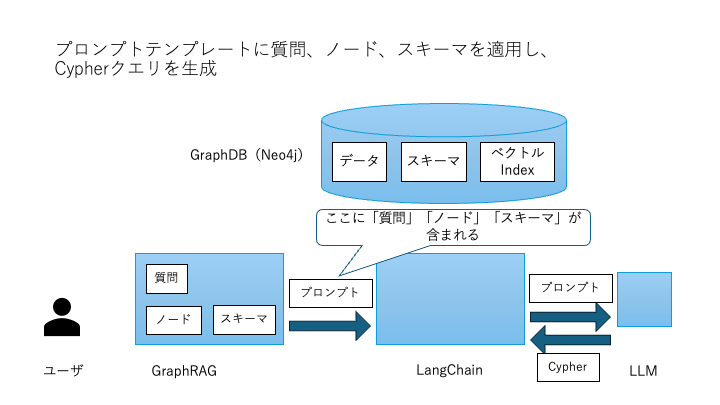
Cypherクエリ生成
「質問」「関連ノード」「スキーマ」を入力としてLLMに渡し、LangChainのプロンプトテンプレートでCypherクエリを自動生成します。
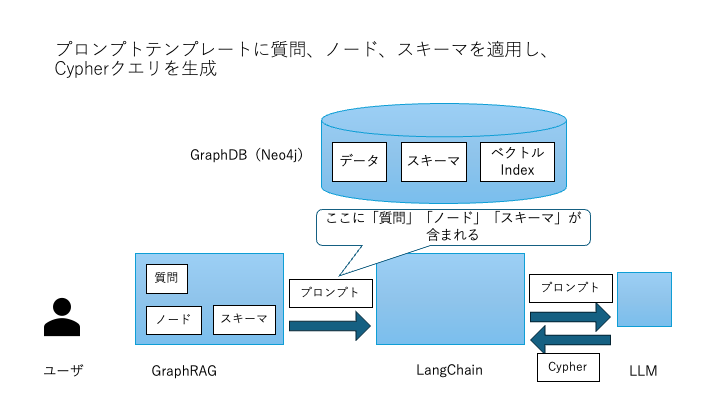
生成されたCypherクエリの例:MATCH (c:CustomerMaster {name: "東日本エンジニアリング"})<-[:CUSTOMER]-(p:Project)-[:EQUIPMENT]->(e:Equipment) MATCH (e)-[:BOM]->(b:BOM)-[:MATERIAL]->(part:Part)-[:MASTER]->(pm:PartMaster) RETURN pm.name, part.lotNo -
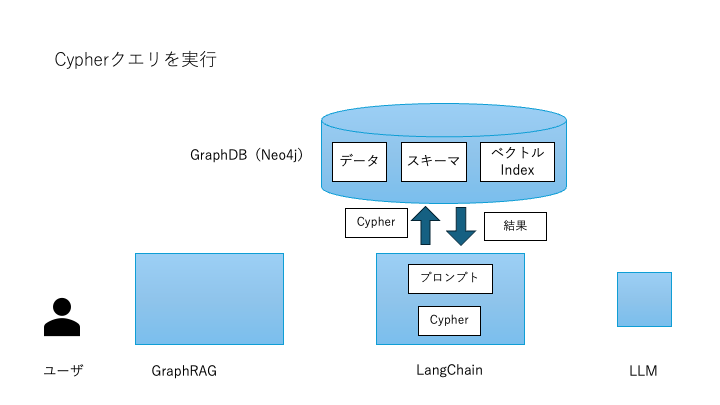
クエリ実行と結果取得
Neo4jでCypherクエリを実行し、検索結果(部品リスト、顧客情報など)を取得します。
-
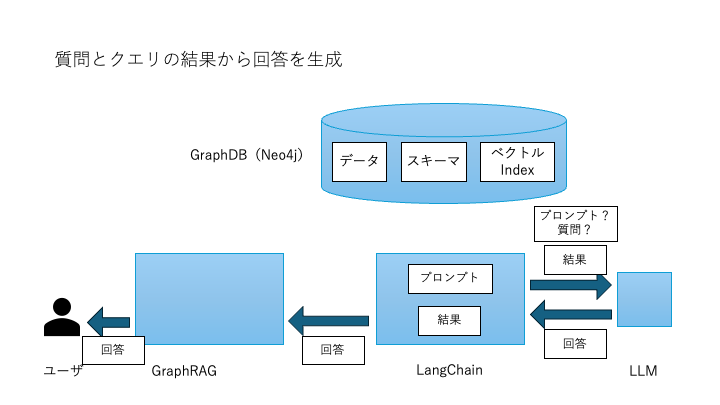
回答生成
最後に、質問文とクエリ結果を入力としてLLMが自然言語の回答を生成します。
→ ユーザーはグラフ構造を意識せず、自然言語で質問するだけで高度な検索が可能になります。
技術的特徴と利点
- 構造データと自然言語の橋渡し
スキーマ+ノード情報をLLMに渡すことで、誤ったCypherを生成しにくくしています。 - 意味検索の強化
ベクトルIndexを利用することで、「曖昧な部品名」や「似た表現」を含む質問にも対応可能。 - 再利用性の高いアーキテクチャ
これらの組み合わせは、他のドメインにも容易に転用できます。- Neo4jを使ったグラフDB管理
- LangChainによるプロンプト設計
- LLMを使った動的クエリ生成
まとめ
dbtsのGraphRAGデモプログラムは、
- ベクトル検索で質問に関連するノードを特定し、
- スキーマ情報を基に正確なCypherを生成し、
- Neo4jでクエリを実行、
- LLMで回答を自然言語に整形する
というフルパイプラインを実装しています。
デモ用のプログラムのため精度はそれほど高くありませんが、「構造化データの探索を自然言語で実現する仕組み」を実現する際には参考になると思います。